Idempotent Event Ingestion in a Multi-Producer System
“Details matter, it's worth waiting to get it right.” ― Steve Jobs
The Problem
During the early stages of building a new esports analytics platform that integrates with the Overwolf API , I ran into a challenge with event ingestion. When a single player streams events to our API, everything works as expected. However, as this increases to more than one user per game, the system risks recording duplicate events unless deduplication is handled explicitly.
For example, if User A defeats User B in a round, and all 10 users have the app, then naively our database will be bombarded with 10 independent writes for the same event. This poses a serious issue for an analytics platform.
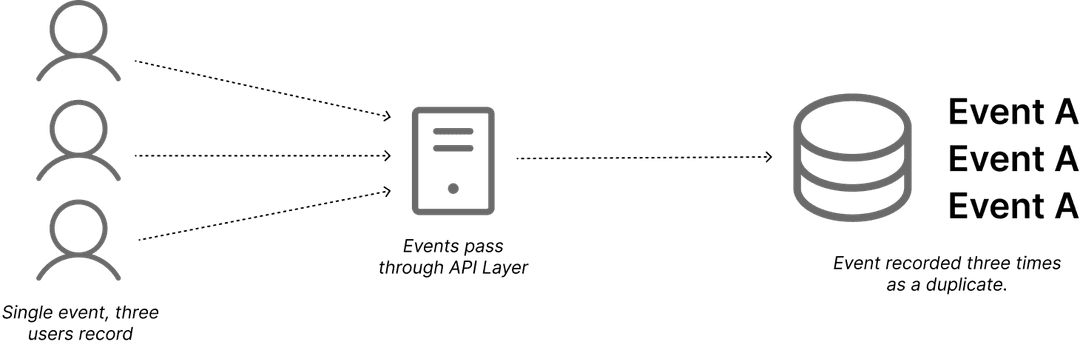
The first approach I considered was fingerprinting events. A deterministic algorithm (like SHA256) could be run using the attacker, victim, match_id, and round_id fields. But this introduces a new complication: in this game, players can be revived, meaning the same four values can appear multiple times in a round.

The obvious next step here is including a “time_into_round (ms)” field in the fingerprint. This could distinguish repeated kills. However, since each user's machine has independent clocks, this value cannot be fully trusted due to clock drift . Bucketing the times into ranges, e.g., “20-22 seconds”, helps but introduces edge cases, such as kills at 21.9s vs 22.1s falling into different buckets. Still far from ideal!
Even after solving these logical issues, there's a performance concern: each write still triggers a uniqueness check in the database. While PostgreSQL handles indexed uniqueness efficiently, sending up to 10 identical events per match still adds latency, network egress costs, and write load. At scale, this pattern can overwhelm the database.
The Solution
Okay, so far, all I have done is introduce issues and roadblocks. So how did I actually solve it?
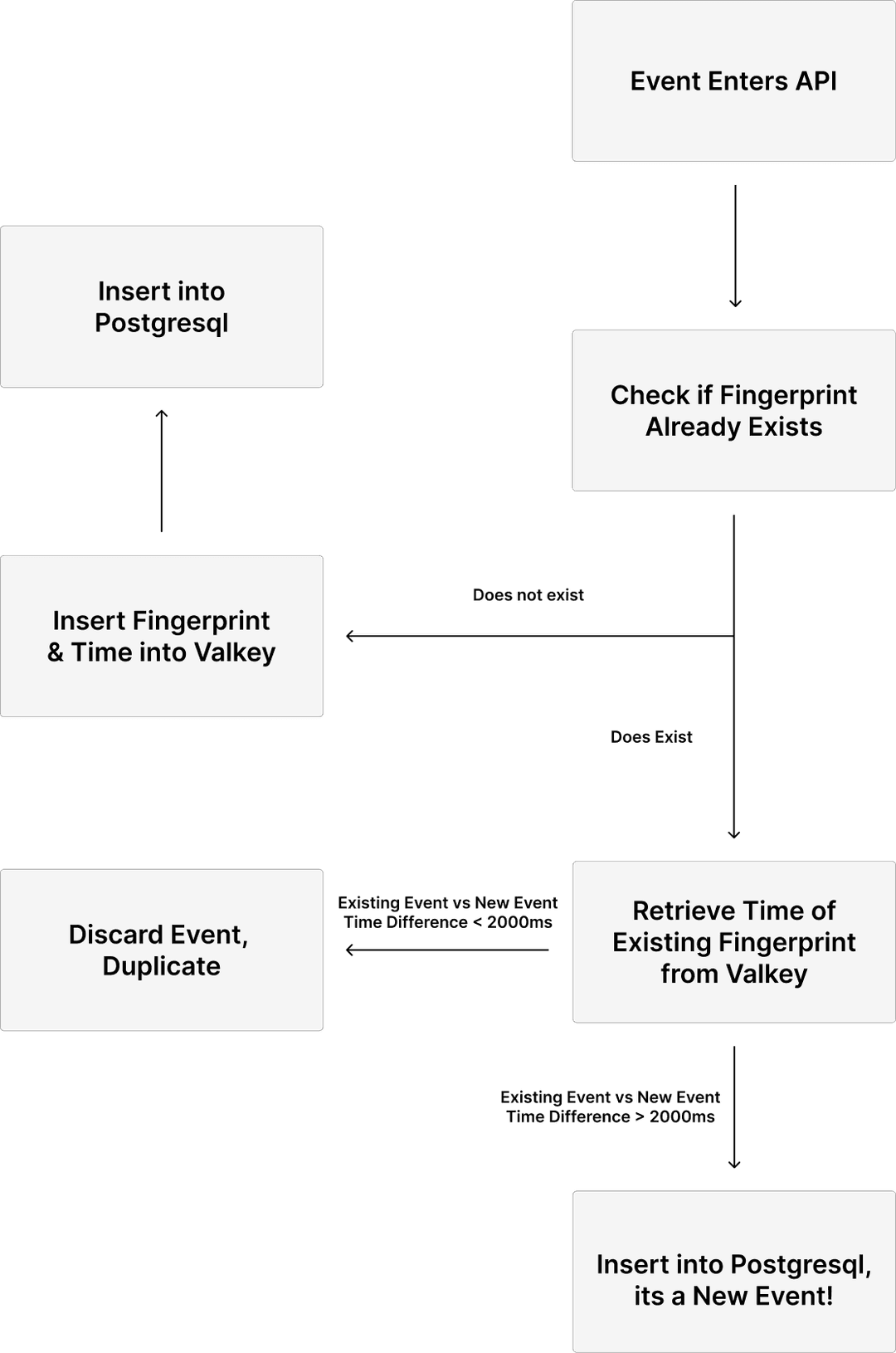
I used Valkey , an in-memory database with a hashmap data type. Before inserting an event into the database, the system checks our Valkey instance to find out whether the event has already been processed.
Here's how it works:
- Fingerprinting: We create a fingerprint using the original four values: attacker, victim, match_id, and round_id.
- Valkey check: We attempt to insert this fingerprint into Valkey, using the fingerprint as the key and time_into_round (ms) as the value.
- If the key does not exist, this is a new event. We insert the key/value pair into Valkey and write the event to our database (without needing a uniqueness check).
- If the key already exists, we retrieve the stored time_into_round value. If the new event occurs within ~2 seconds of the existing one (roughly the duration of any revive animation), we safely ignore it. This avoids the “0.9 vs. 1.1 seconds” bucket edge cases discussed earlier.
- If the events are more than ~2 seconds apart, we treat it as a legitimate new kill, likely resulting from a revived player, and insert it into the database.
Currently, our backend is built in FastAPI with Python, ingesting events through our API and then into a single worker node that processes a queue (also in Valkey). This serializes execution, naturally preventing race conditions during our deduplication checks.
If the platform ever did need to scale to more workers and Valkey instances, the next step is partitioning the worker nodes that handle events by a hash of the match_id , ensuring events from the same match are processed in order, one by one.
Using Valkey as an in-memory layer lets us deduplicate events in real time, avoid timing edge cases, and eliminate unnecessary database checks. The system is fast, accurate, and can scale safely across multiple workers, making our platform reliable and efficient!
Note:
Some other considerations when designing the solution were issues regarding database write fails and Valkey crashes. These are obviously issues that need to be addressed (and have been!), but I didn't want to ramble on too long about explicit error handling.