Writing a Relational Database in Rust [Part 1]: SQL Parsing
"If you really want to understand something, the best way is to try and explain it to someone else." ― Douglas Adams
Note:
Much of the foundational thinking behind this project comes from the book Designing Data Intensive Applications, along with blog posts from Yash Agarwal, Phil Eaton, and PlanetScale.
In this series, I'll be building a relational, ACID -compliant database from scratch in Rust. The accompanying GitHub repo contains the full implementation and will evolve asynchronously alongside these posts.
The first challenge in building a database engine is determining how a user will interact with the system. In most cases, that means SQL. A database engine must take a raw SQL string, parse it, and construct an Abstract Syntax Tree (AST) that represents the intent of the query in a way the engine can understand. While production databases rely on existing Rust crates , I chose to implement a minimal parser myself to better understand that translation layer.
That being said, this section of the project will be intentionally minimal. It won't cover query optimization or a full tokenizer . For simplicity, the engine will only initially support SELECT, INSERT, DELETE, and CREATE commands. UPDATE, DROP, GRANT, REVOKE, and other more complicated commands will be added as the project evolves.
Step one here is creating the entry point to the engine. We do this with an infinite loop, a few objects that need to exist for the duration of a single request, and a call to our handle_sql_parser() function.
Note:
Some error handling and other Rust intricacies have been left out for readability. This will remain the case throughout this series. If you want to see the full implementation, refer to the GitHub repo.
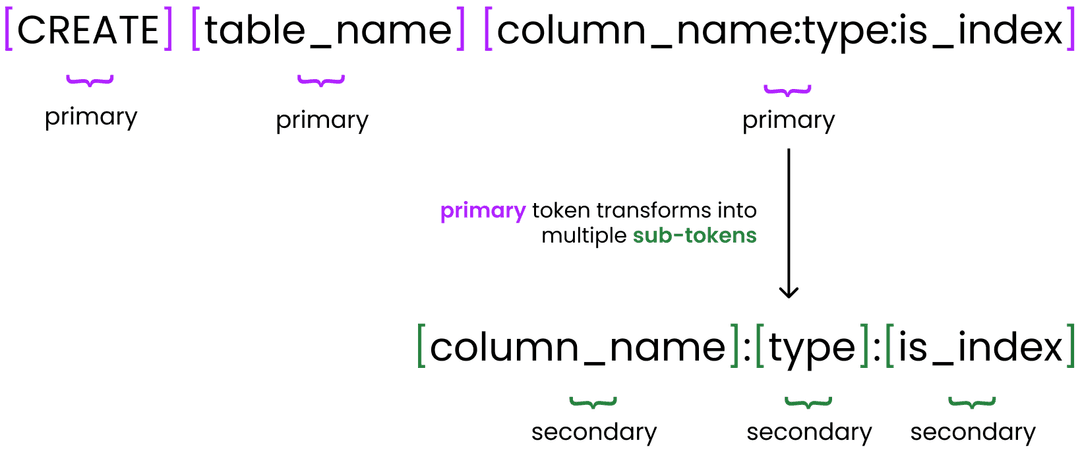
Next, we call handle_sql_parser() to tokenize the user's input by splitting on spaces. Each space-delimited segment is treated as a primary token, representing a top-level component of the command.
This structure also allows certain primary tokens to contain their own internal hierarchy. As shown below, colons (:) are used to define sub-tokens within a primary token, enabling us to encode structured metadata (such as field name, type, and constraints) inside a single space-delimited segment.
Awesome. Now we know how we're going to parse user commands and ultimately construct an AST. To determine whether a token is a command, filter, operand, or something else, we use enums. Currently we have six in the /src/core/enums folder. Their basic definitions are:
Using these enums and token matching, we sequentially scan the entire SQL command, looking for relevant primary tokens. If we encounter an OP or VALUE token during the primary parsing loop, we treat it as malformed, since those should only appear within sub functions for primary commands. Upon finding a relevant token (CMD or FILTER), we call a function to handle it explicitly using a match statement. Below is the full handle_sql_parser() function.
Within the match_filter() and match_command() functions called in handle_sql_parser(), we perform a secondary match based on the specific token type that was identified during the primary scan.
Each handle_*() function is implemented differently depending on the token. Some are very straightforward. For example, in the case of DELETE, we simply set the command type on our QueryObject instance and continue iterating through the remaining tokens.
Other commands are more complicated. For example, SELECT requires additional state tracking. We first set the command type in the query instance to SELECT. Then, we treat the subsequent tokens as column names to be selected (with * acting as a protected value representing all columns) until we encounter another primary token type, such as FROM.
The other implementations, for WHERE, FROM, INSERT, CREATE, are shown below:
After iterating through all tokens and erroring whenever there is a malformed request, we end up with our AST. This AST will then be used in future sections to decide what our database engine should actually do after the user input.
The shape of this AST is important. It defines what kinds of queries the engine is able to execute. The structure is intentionally simple for now, but this minimal structure still allows us to do basic commands that all SQL databases should be capable of.
Below are the supported commands, their syntax, and the AST each produces:
Create
syntax
CREATE table_name column_name:type :is_index
Select
syntax
SELECT column_name FROM table_name WHERE field op value
Insert
syntax
INSERT table_name value1:value2:...
Delete
syntax
DELETE FROM table_name WHERE field op value