Writing a Relational Database in Rust [Part 2]: SQL Pages + Command Handling
"...And that's really the essence of programming. By the time you've sorted out a complicated idea into little steps that even a stupid machine can deal with, you've certainly learned something about it yourself." ― Douglas Adams
Note:
This blog post is part two in a multipart series about building a relational database from scratch in Rust. Part one is linked below and goes over using a tokenizer to build an Abstract Syntax Tree (AST) to get to where we are in this post.
After the AST has been finished, we are able to send the object into our handle_query() function. This function is a match statement that executes on one of the supported commands . Here is a refresher on what that AST object could look like, along with the handle_query() code:
CREATE
The first match statement we need to cover is CREATE, that way it will be easier to understand future sections.
Our create_new_table() function only needs to do two things.
First, it should create a metadata object that will be put in our catalog as a single entry. This catalog entry will contain the table name, all column names, data types, and if a column will have an index. After the entry has been created, it is saved to a file under /database/catalogs to be stored on disk.
In a production database, our catalog would be stored more efficiently , and also have much more information . For our purposes, we just need to keep track of basic table information in a human readable format.
Next, it should create the table itself as a .practice file, where future data will ultimately be stored. Right now, it is just an empty file with 0 pages .
INSERT
After creating a table, we will want to insert data into it. At a high level calling insert_new_data() will need to do a few things:
- Retrieve the target table's schema from the catalog entry.
- Transform the data from the input format to a byte format by calling
build_row_byte(). - Open the table's file under tables/{table_name}.practice, and get the current length of the file.
- Call the
find_page()function, which scans our table file to find the first slot to put our data in, or creates a new page if there is no space.
Now, for the details. build_row_byte() is a fairly uninteresting section of code. In short, what it does is takes an input of the row to be inserted, checks that the values are valid, and moves them from string inputs to their proper byte conversions . Then, it calculates the header bytes. One byte for the size of the header [index 0], a second byte for the number of columns [index 1], and then a variable number of bytes for the length of each column's data [index 2...2+N]. Then returns the result to our main insert function.
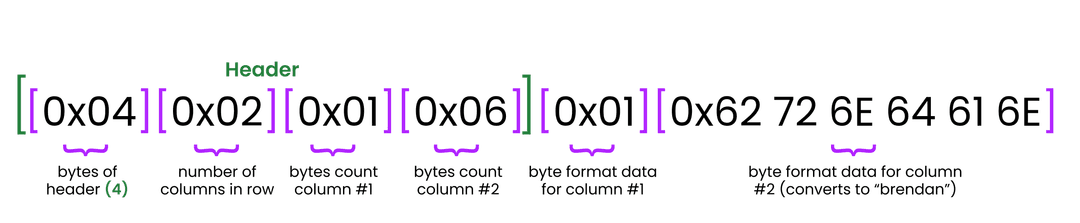
Below is a visual representation and example of what a row in byte form looks like. This is a row with two columns, "column_id" and "first_name", where the first column is an i8 type type and the second column is a string type. When we insert a row with the id "1" and the name "brendan", the below is what is returned. The header is 4 bytes, and the data itself is 7 bytes.
Here's the code for the above transformation:
Now that we have our row in byte format, we need to find somewhere in our table to put it. Back in the insert_new_data() function, we now call find_page() to do that.
In find_page(), the first check we do is to see if the file_length is '0'. If it is, we know we need a new page, and can immediately call build_new_page().
I am going to pause the overall flow of this post a bit to go in depth on build_new_page(), as it is perhaps the most important section of code in this entire project. It is what sets the database up for performance, features, etc.
Pages in Relational Databases
Pages are, in short, the smallest chunk of data a database can read to, or write from in a single operation. Even if a user is only reading one row, the entire page that contains that row is brought into memory (off disk). The pages in our implementation are 4096 bytes (4kb). Bytes 0-10 are used for our static sections of the header. The dynamic section of our header keeps track of each row's offset (2 bytes) and row length (2 bytes). The remaining bytes on the page are for the data itself. This means that a single row can have a max of 4081 bytes of data.
Here is a small table showing what each byte of the header is used for:
| Bytes | Field | Description |
|---|---|---|
| 0 | Page ID | Helps find the offset of the page in the file |
| 1 | Row Count | Number of active rows |
| 2-3 | Current Rows Size | Cumulative size of stored rows (determines insert point) |
| 4-5 | Space Remaining | Free space available on the page |
| 6 | LSN | Log sequence number (for future WAL support) |
| 7-8 | Header Size | Total size of the page header (grows with slots) |
| 9-10 | Freed Space | Tracks space from deletions (triggers compaction) |
After the static header, we have a dynamic section of the header: Slots. The slot tells us where each rows data lives. Each slot is 4 bytes: 2 for length of the row it represents, 2 for offset to find the row on the page. Slots point to row data stored from the end of the page backward. We store the length to know how long each row is , and the offset so that we can find and move rows. This helps with compacting pages later when there is a lot of 'free' space on a page, and also makes sure deleted data isn't read after deletion.
We keep track of each of these values for future ease of use. For example, on our insert_new_data() function, we will be able to scan bytes 4 & 5 of each page to see if our new data can even fit on that page. If it can't, we know to go to the next page in the table. IE, if we visualize our table as one long sequence of bytes we can check every 4096 bytes for a value, rather than scanning every byte on every page to find enough open space.
After a page is created, it is simply appended to our table's file, and written back to disk using insert_page().
Now back to find_page(). If the file_length is not '0', we can attempt to insert our new data into an existing page. We do this by traversing through all existing pages in a loop . We then check the correct 4096 bytes in the primary table file, read bytes 4-5 for space remaining, and compare it to our row size.
If there is enough space in the currently scanned page, we update relevant metadata:
- Update the page headers (offset, space remaining, etc)
- Add the new slot to the dynamic section of the page header
- Add the row data to the back of the page.
If there isn't enough space, we simply go to the next page. If no pages have enough space, we create a new one with build_new_page()!
SELECT AND DELETE
The next match statement to cover is SELECT , where we call the read_data() function, this will:
- Retrieve the table schema from CREATE .
- Get the path to that table, and open it using
File::open. - Retrieve the file length.
These are then passed into parse_sequential() alongside action: select and the query object.
parse_sequential() is used in both DELETE and SELECT. At a high level what it does is go through each page, check page headers to then walk through the table row by row, check for any conditionals (where clauses), and then either delete or print (depending on the action).
If the action is SELECT, all it does is print the row in terminal (for now), and if the action is DELETE, it updates all relevant header data, removes the slot, and "frees" the data.
It also keeps track of a "page is modified" variable, which then rewrites the page back to disk.
Note:
Much of this functionality will change in future versions. Namely we will make use of the "dirty" bit to keep pages in the buffer pool, and only update and flush as needed / alongside the WAL. Secondly, the "SELECT" algorithm will correctly use B/B+ trees when a column we are searching for is indexed.
Here are the relevant sections of code for parse_sequential():